This article takes a shallow dive into enabling Nvidia GPU support inside docker containers, summarizing what Nvidia’s confusingly-named packages do, and demystifying all the “tricks” surrounding the topic.
It all started when I was trying to deploy Plex in Docker: there are so much conflicting information, deprecation and hacks & workarounds. Here’s my findings in an afternoon I’ll never get back.
All information presented in this article is up to date as of June 2020. Due to the constant development around the topic, I would recommend checking these sources for the most up-to-date information:
- Official nvidia-docker repo, however is a bit chaotic at the moment due to multiple versions sharing the same doc.
- This issue regarding docker-compose support for
--gpus.
Table of Contents
- Table of Contents
- Testing environment
- The two ways of enabling GPU support
- Running nvidia/cuda based images
- Dockernized telegraf with nvidia-smi
- NVENC/NVDEC
- Conclusions
Testing environment
- Debian 10 “Buster”
- Nvidia GPU driver 440.82
- Docker 19.03.11, Docker Compose 1.26.0
nvidia-container-toolkit1.1.2,nvidia-container-runtime3.2.0- Quadro P400
The two ways of enabling GPU support
Using nvidia-container-runtime
Make sure nvidia-container-runtime is installed. Instructions
To use the runtime, specify --runtime=nvidia in the docker run command:
docker run --rm --runtime=nvidia nvidia/cuda:10.0-base nvidia-smi
For more customization, refer to NVIDIA/nvidia-container-runtime. You’ll likely need to set NVIDIA_VISIBLE_DEVICES and NVIDIA_DRIVER_CAPABILITIES.
This is also available in Docker Compose (only in v2.3, v2.4):
version: "2.3"
services:
nv:
image: nvidia/cuda:10.0-base
command: nvidia-smi
runtime: nvidia
Using built-in Docker GPU support
Since built-in GPU support has been added in 19.03, the use of --runtime=nvidia is now deprecated. To utlize the built-in GPU support, you’ll need to install thenvidia-container-toolkit package.
Simply use --gpus to specify GPU support:
docker run --rm --gpus all nvidia/cuda:10.0-base nvidia-smi
For more detailed use of --gpus, refer to Docker’s docs
However, this has not been supported by Docker Compose yet (from what I can tell from This issue, it’s due to API limitations at the moment), so runtime: nvidia is still the way to go, when using docker-compose.
TL/DR
| Argument | Deprecated | Docker Compose |
|---|---|---|
--runtime=nvidia |
Since 19.03 | Supported (v2) |
--gpus |
No | Not Supported |
The nice thing is, --gpus and --runtime=nvidia can both be available without conflict.
Also, there’s this nvidia-docker2 that keeps appearing in the docs. It’s the old nvidia runtime package. Just use nvidia-container-toolkit or nvidia-container-runtime.
Running nvidia/cuda based images
Here’s a simple tensorflow demo:
docker run --gpus all -it --rm tensorflow/tensorflow:latest-gpu \
python -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"
There should be lines like Created TensorFlow device ... -> physical GPU ..., and prints a “tf.Tensor” at the end.

*Note: this requires AVX support, if you’re using this from a QEMU VM you’ll need to switch to host (or one that supports AVX) in CPU settings.
Dockernized telegraf with nvidia-smi
Now with gpu support activated at runtime, some applications can use the GPU’s functionalities as if they’re running directly on host.
Here I’m using telegraf to collect nvidia-smi metrics.
version: "2.3"
services:
influxdb:
# ...
telegraf-nvidia:
restart: always
image: telegraf
runtime: nvidia
volumes:
- ./telegraf_nvidia.conf:/etc/telegraf/telegraf.conf:ro
environment:
NVIDIA_VISIBLE_DEVICES: all
Notice the NVIDIA_VISIBLE_DEVICES: all: this is necessary (when using runtime: nvidia) for the runtime to present the GPUs to the container. If you need any other capabilities besides UTILITY, you’ll need to add NVIDIA_DRIVER_CAPABILITIES: all. Check here.
*Note: due to namspacing for the containers, nvidia-smi can only list processes running in their own container, therefore stats like top processes won’t be complete if those other containers are also utilizing the GPU. Hardware stats like GPU clocks, utilization, temperature and fan speed are still available though.
NVENC/NVDEC
For NVENC/NVDEC to work, packages libnvcuvid1 & libnvidia-encode1 are required on host. For the latest Video Codec SDK 9.1, Nvidia Driver 435.21 or newer is required.
*Also, if you’re going for multiple concurrent NVENC/NVDEC sessions, I recommend checking out keylase/nvidia-patch for getting around the driver’s session limit.
ffmpeg
For ffmpeg to work with NV GPU, it needs to be compiled with NV support enabled (see here). Beware that ffmpeg from many distros’ main repo won’t have this support due to non-free.
I’m using linuxserver’s linuxserver/ffmpeg image, which was configured to use --runtime=nvidia, but here using --gpus all it works just fine.
Let’s try a simple H264 to HEVC transcode:
docker run --rm --gpus all -v $(pwd):/work linuxserver/ffmpeg \
-vsync 0 -hwaccel cuvid \
-c:v h264_cuvid -i /work/input.mp4 \
-c:v hevc_nvenc -c:a copy /work/output.mp4
Here using --gpus all to specify the container to use all GPUs, and -hwaccel cuvid to utilize the hardware accelerated video processing chain (frames stay inside GPU memory), h264_cuvid and hevc_nvenc to utilize hardware encoder & decoders. For more info, check NVIDIA FFmpeg Transcoding Guide.
There’s no need to provide capabilities=video here because the image already have NVIDIA_DRIVER_CAPABILITIES=all set.
Plex Media Server
Finally, back to the reason I started all this: I just wanted to deploy PMS in my docker host. It turns out it’s really simple:
version: '2.3'
services:
pms:
image: plexinc/pms-docker
runtime: nvidia
environment:
# ...
NVIDIA_VISIBLE_DEVICES: all
NVIDIA_DRIVER_CAPABILITIES: video
# ... other things like volumes, ports, ...
# ... other services ...
version: '2.3'so we can use theruntime: nvidiaruntime: nvidiaso that nvidia-container-runtime can hook the driver & librariesNVIDIA_VISIBLE_DEVICES: allso all GPUs are made available to the container.NVIDIA_DRIVER_CAPABILITIES: videoso Video Codec SDK can be used.
No need to pass devices into the container, nor to rebase the whole image on nvidia\cuda. Also here I’m using the official plexinc/pms-docker image, indicating it definately has GPU support.
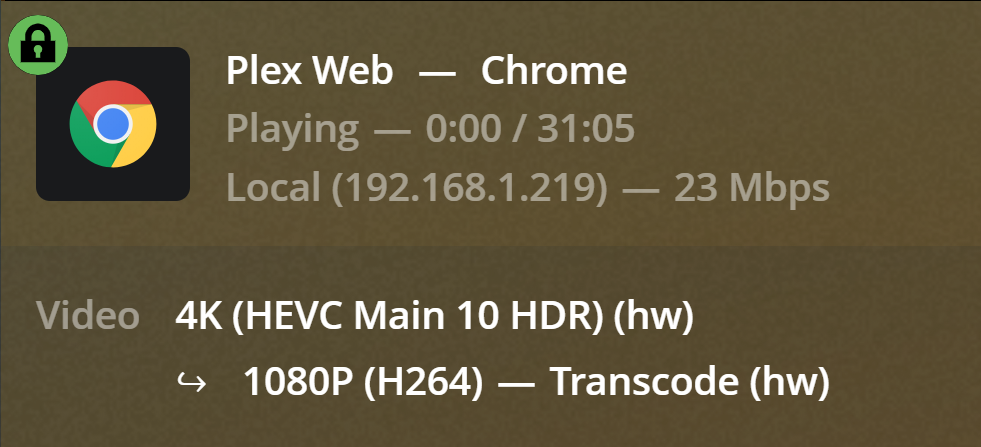
Let’s try --gpus all:
docker run --rm --gpus "all,capabilities=video" \
--network host -v /data:/data -e PLEX_UID=1000 -e PLEX_GID=100 \
plexinc/pms-docker
This works too. Here we’re specifying capabilities=video to make sure container can access video codec API (otherwise it defaults to utility as the image did not set NVIDIA_DRIVER_CAPABILITIES).
Using -e NVIDIA_DRIVER_CAPABILITIES=video works as well.
However, there is still a problem: GPU stays in P0 after stopping the transcode. After a bit of digging around, this seems a Nvidia driver issue. Plex tests transcode capabilities when the first transcode starts, by attempting to open a decoder or encoder, and the device remains in a high power state until the process exits. According to Plex staff, this should be fixed in later drivers.
Conclusions
This has been a pretty interesting dive into Nvidia’s container support. However I haven’t touched on how the runtime actually works (I’ll probably do another article later), but the findings have been quite simple:
- Install Nvidia drivers and libraries
- Install
nvidia-container-toolkit&nvidia-container-runtime - Use
--gpus allif using latest versions of Docker, or - Use
runtime: nvidiain Docker Compose. - Setup runtime arguments like
NVIDIA_DRIVER_CAPABILITIES,NVIDIA_VISIBLE_DEVICESaccordingly.
Again, if you’re referencing this in the distant future, please check sources listed throughout the article for most up-to-date information. Also, have humans landed on Mars yet?